突破多智能体系统边界,开源方案OWL超越OpenAI Deep Research,获17k star
港大、camel-ai 等多家机构联合提出了一种名为新的名为 Workforce 的创新多智能体框架,以及配套…

港大、camel-ai 等多家机构联合提出了一种名为新的名为 Workforce 的创新多智能体框架,以及配套…

当前大型视觉语言模型(LVLMs)普遍存在“物体幻觉”问题:模型会凭空生成图像中不存在的物体描述。为了高效地实…

在开源模型领域,DeepSeek 又带来了惊喜。 上个月 28 号,DeepSeek 来了波小更新,其 R1 …

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言…
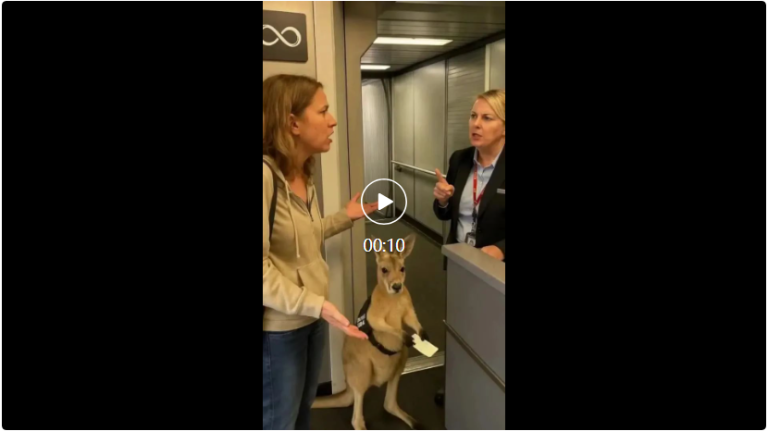
假作真时真亦假,无为有处有还无。 200 多年前,曹雪芹在《红楼梦》中写下这样一句话:假作真时真亦假,无为有处…

近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。然而,在图像生成模…
编辑 | 白菜叶 细胞间通讯(CCC)是确保生物系统和谐运作的基本生物学过程。 越来越多的证据表明,同一类型或…

AI独角兽企业九章云极DataCanvas在“九章云极智能计算论坛”上正式发布新一代全栈智能计算云平台——九章…

AI 不缺模型,缺的是能把它带到真实世界里的「玩家」,会是你吗? 高考刚刚结束,AI 正在进入「真实世界的考试…

大赛报名于2025年6月25日截止,感兴趣的团队尽快报名参赛。 百舸争流,「启智杯」初赛火热进行中 随着人工智…