准确率72.46%!中南大学团队提出多源相似性融合模型MSSF,精准预测药物副作用频率
编辑丨% 生病吃药的时候,常会在说明书上看到对此药副作用的说明。对副作用的识别研究有助于药物开发过程中风险的降…

编辑丨% 生病吃药的时候,常会在说明书上看到对此药副作用的说明。对副作用的识别研究有助于药物开发过程中风险的降…

编辑 | 白菜叶 近期,美国西北大学(Northwestern University)生物物理学家开发了一种新…
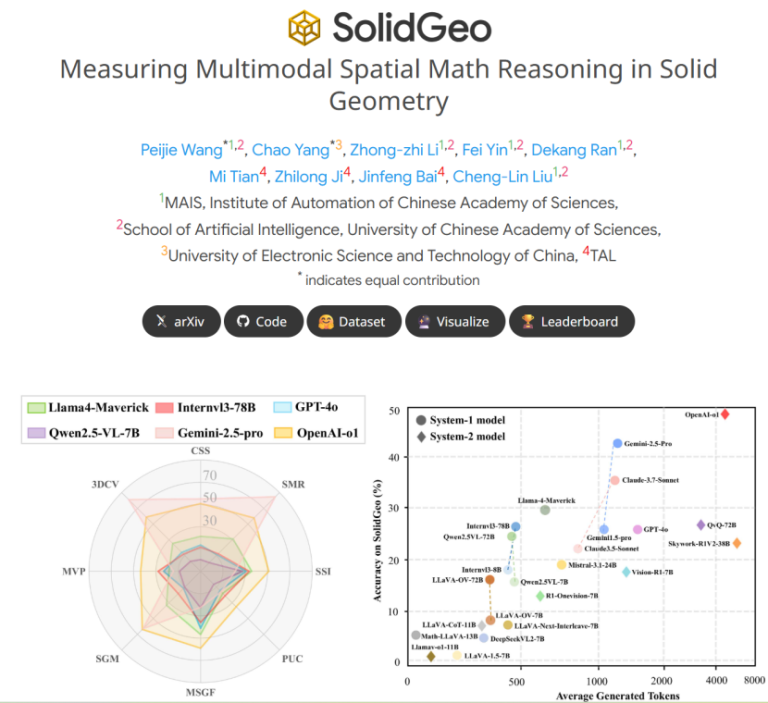
最强模型OpenAI-o1准确率不足50%,开源模型“集体翻车”,多模态大模型(MLLM)立体几何数学推理能力…

2025 年已经过半,AI 领域依旧保持着高速发展的势头。从大模型的演化,到多模态系统的融合,再到推理能力与可…

只需要三条轨迹,就能取得 96.8% 的成功率?视觉干扰、任务组合等泛化场景都能轻松拿捏?或许,3D VLA …

在当今科技飞速发展的时代,机器人在各个领域的应用越来越广泛,从工业生产到日常生活,都能看到它们的身影。然而,现…
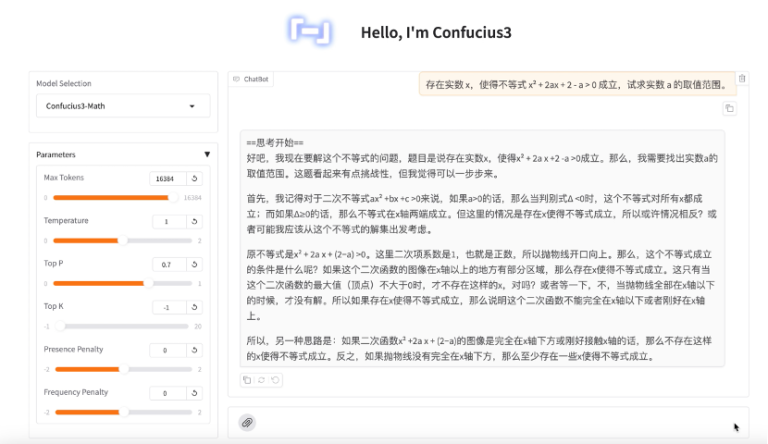
6月23日,网易有道宣布正式开源“子曰3”系列大模型的数学模型(英文名称Confucius3-Math)。这是…

本文的第一作者罗琪竣、第二作者李梦琦为香港中文大学(深圳)计算机科学博士生,本文在上海交通大学赵磊老师、香港中…

本文共同第一作者为张均瑜与董润沛,分别为伊利诺伊大学厄巴纳-香槟分校计算机科学研究生与博士生;该研究工作在伊利…
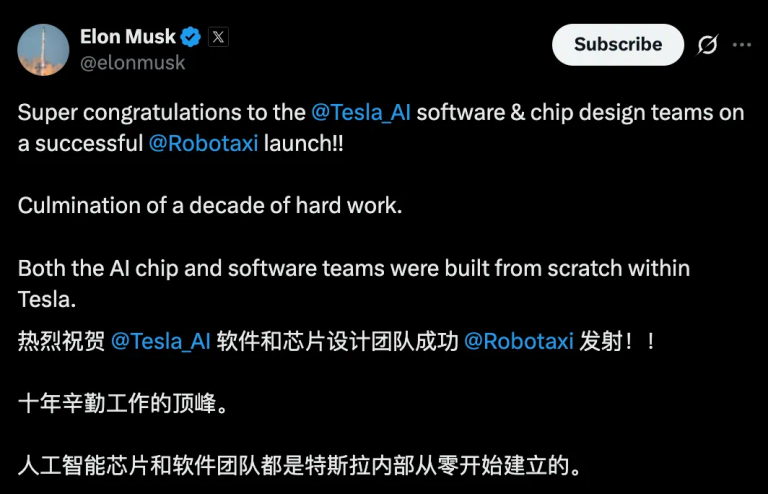
马斯克终于不「画饼」了!4.2美元坐特斯拉Robotaxi初体验:平稳但尚不成熟。 马斯克兑现了承诺。 早在十…