原来你是这样的外滩大会!
家人们谁懂啊 MBTI 测不准可能是你分身不够多! 😂 作为全球金融科技和前沿科技大会,我外滩大会直接把 16…

家人们谁懂啊 MBTI 测不准可能是你分身不够多! 😂 作为全球金融科技和前沿科技大会,我外滩大会直接把 16…



近日,人工智能教父杰弗里・辛顿(Geoffrey Hinton)在接受媒体采访时,透露了一则趣闻。 他说在日常…

本文第一作者为新加坡国立大学博士生 张桂彬、牛津大学研究员 耿鹤嘉、帝国理工学院博士生 于晓航;通讯作者为上海…

打开多模态自由创作的大门。 谷歌 Nano Banana 掀起的全球创作狂欢尚未消退之际,字节又玩了把大的。 …
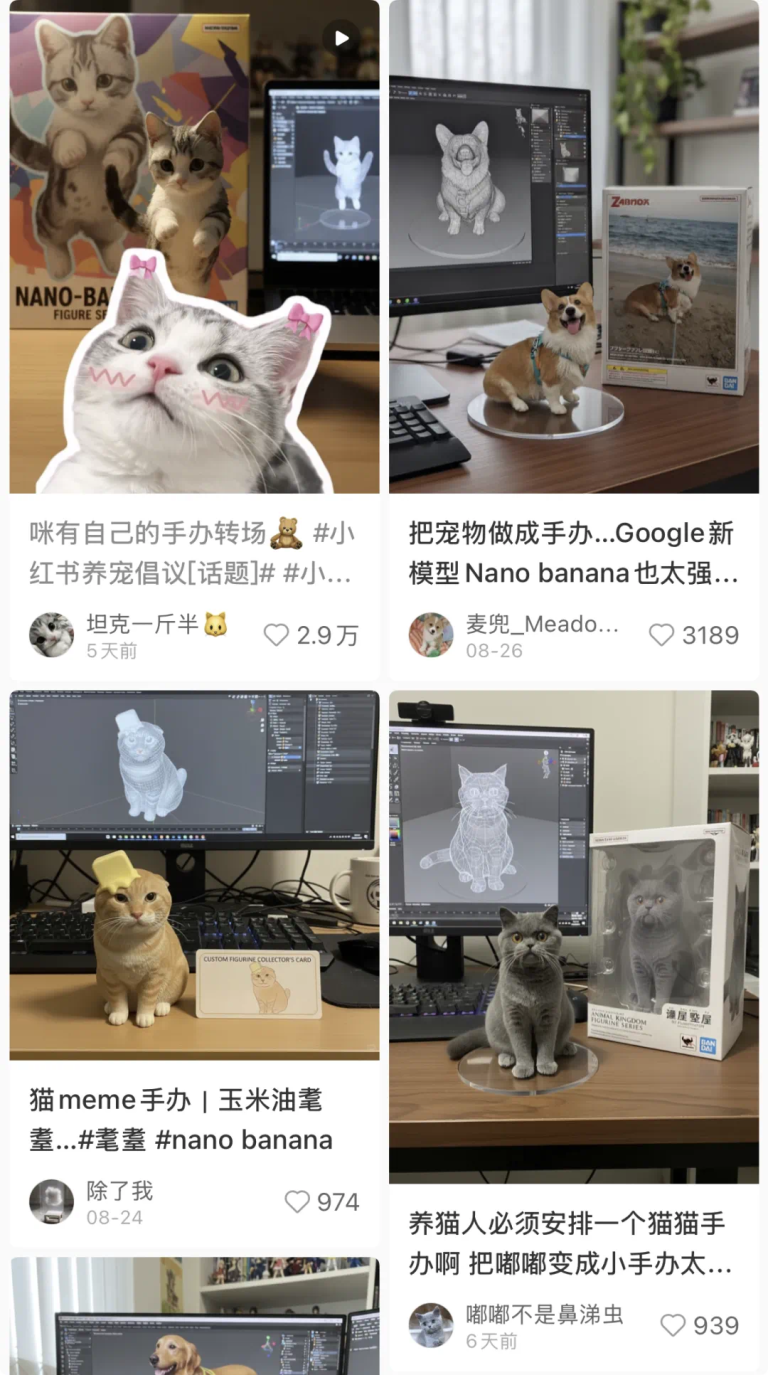
好玩好用的明星视频生成产品再更新,用户操作基础,模型技术就不基础。 熟悉生成领域的读者们最近都被谷歌的一只纳米…

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。 近期,Meta Superintelligence…

在多模态大模型的基座上,视觉 – 语言 – 动作(Visual-Language-Ac…

作者丨论文团队 编辑丨ScienceAI 在传统印象中,科学发现是一条漫长而艰辛的道路,需要科学家投入毕生心血…