以玩促学?游戏代码驱动数据合成,提升多模态大模型通用推理
如果告诉你,AI在推箱子等游戏场景上训练,能让它在几何推理与图表推理上表现更好,你会相信吗? 复旦NLP实验室…

如果告诉你,AI在推箱子等游戏场景上训练,能让它在几何推理与图表推理上表现更好,你会相信吗? 复旦NLP实验室…

本文第一作者为 Virginia Tech 计算机系博士 Candidate 曾欣悦,研究聚焦于提升大语言模型…

编辑 | 萝卜皮 人工智能(AI)的进步有望实现自主科学发现,但大多数系统仍在重复训练数据中潜藏的知识。 几个…

编辑 | ScienceAI 随着有机合成、材料开发、药物筛选等领域走向高度自动化,实验流程的标准化与可执行性…
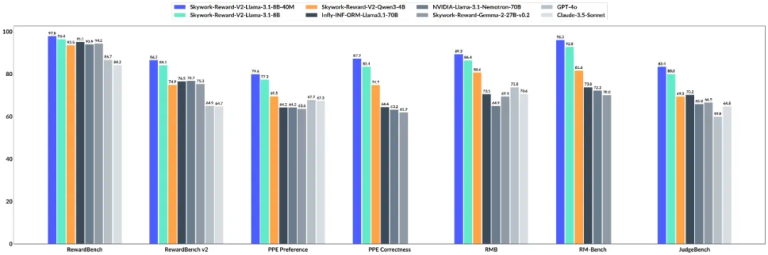
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RL…

这个AI让打工人「磕头」致谢。 前段时间,我们报道了 5 款大模型参加了今年山东高考的事儿,为了弄清楚各大模型…

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术…
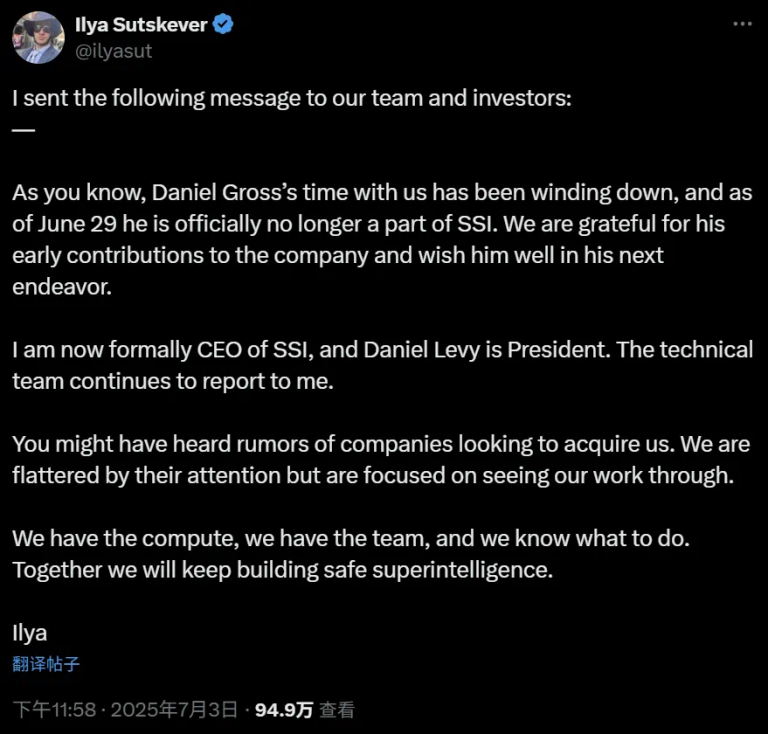
Meta 的挖掘机,终于挖到了 Ilya 大神的头上。 周五凌晨,OpenAI 联合创始人 Ilya Suts…

MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研…

当整个人工智能行业都在为「如何给程序员打造更快的马」而疯狂投入时,一支特立独行的团队选择「直接去造汽车」。 「…