ICML 2025 Oral!北大和腾讯优图破解AI生成图像检测泛化难题:正交子空间分解
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这…

随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这…
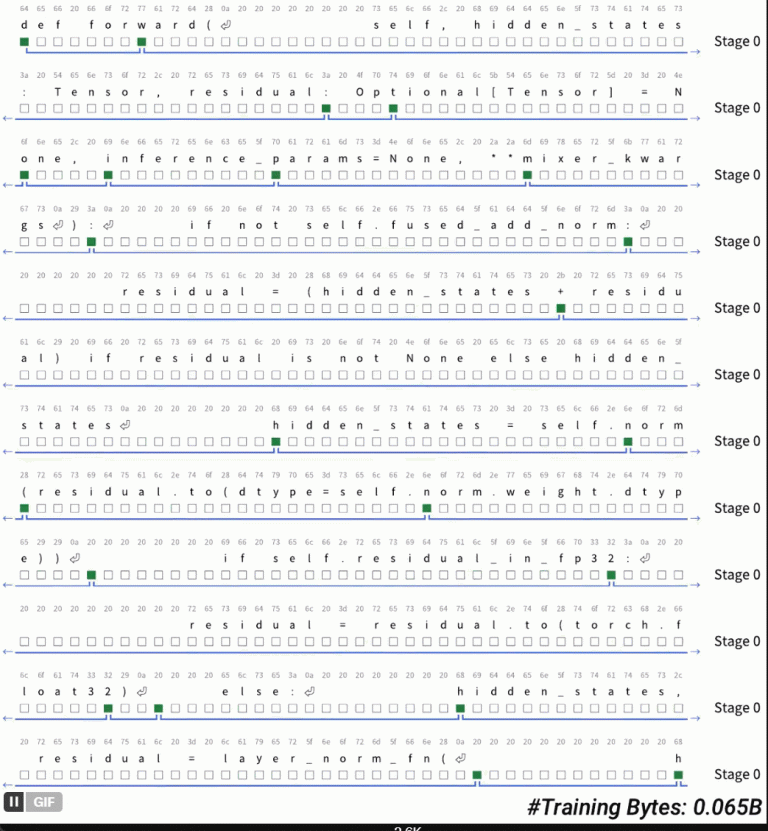
Tokenization,一直是实现真正端到端语言模型的最后一个障碍。 我们终于摆脱 tokenization…

扎克伯格继续「挖啊挖」,这次「又」轮到 OpenAI 了! 据 The Information 报道,近日 M…

论文作者团队简介:本文第一作者周鑫,共同第一作者梁定康,均为华中科技大学博士生,导师为白翔教授。合作者包括华中…

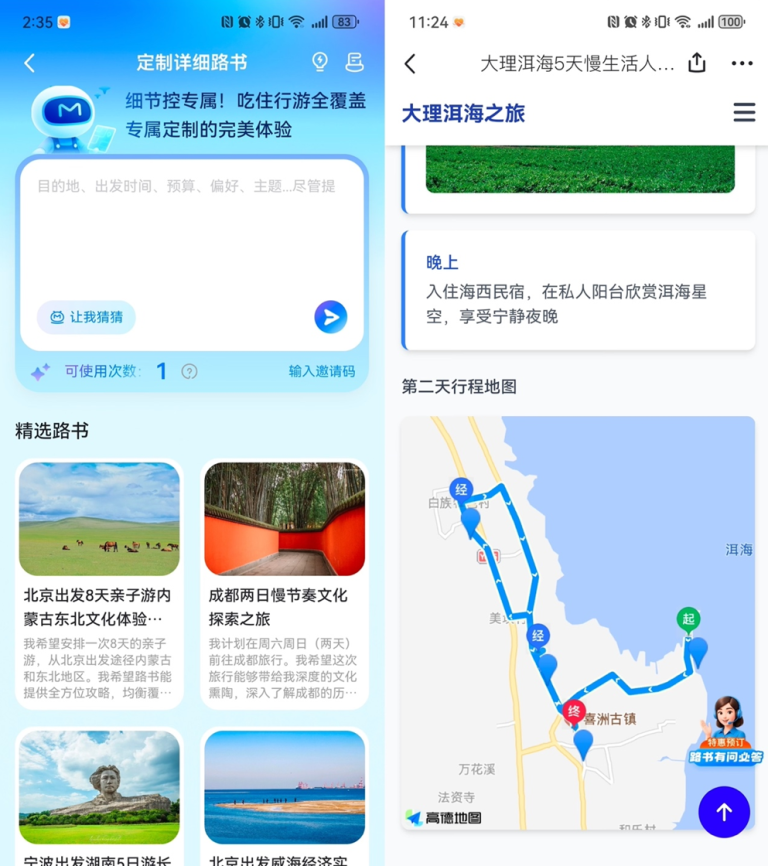
7 月 11 日,马蜂窝的深度个性化的攻略定制产品 “AI 路书” 正式宣布向所有用户开放,同步上线 “AI …

作为 AI 领域最具影响力的学术会议之一,今年 ICML 将于 7 月 13 日至 7 月 19 日在加拿大温…

张剑清是一名上海交通大学在读博士生,获中国人工智能学会「青托」、吴文俊人工智能荣誉博士及国家奖学金。在代码大模…
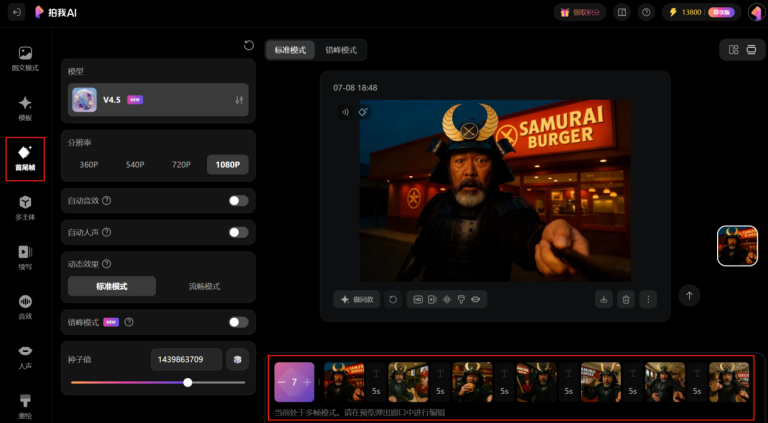
今天,全球超6000万用户的拍我AI(PixVerse)在首尾帧模块中新增「多关键帧生成」功能。用户可上传最多…
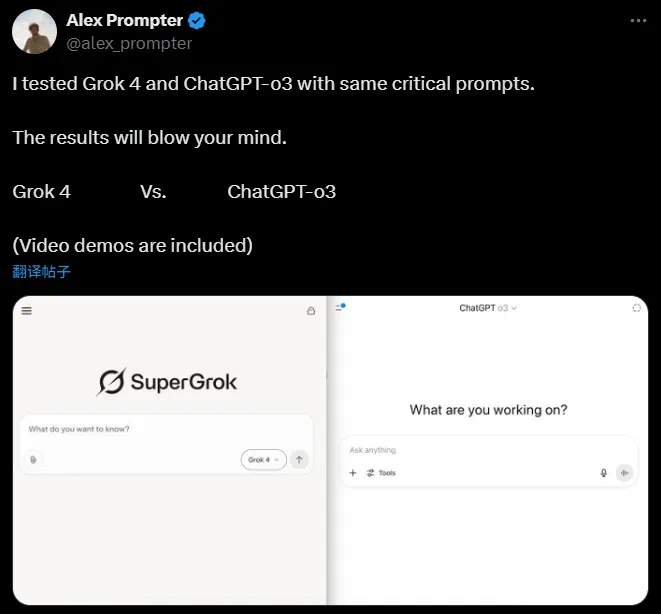
网友氪重金体验Grok4。 昨天,马斯克亮相 Grok 4 发布会,一脸骄傲地表示:Grok 现在所有学科都达…