图灵奖得主Sutton再突破:强化学习在控制问题上媲美深度强化学习?
不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月…

不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月…

本文第一作者唐飞,浙江大学硕士生,研究方向是 GUI Agent、多模态推理等。本文通讯作者沈永亮,浙江大学百…

让 OpenAI 拿到 IMO 金牌的模型,背后居然只有三个核心开发者?这是 OpenAI IMO 团队最近接…

赢了的才是「GPT-5」。 GPT-5 迟迟未现身,网友们开始制作各种梗图「吐槽」: 其实,这几天关于 GPT…

硅谷创业故事大家可再熟悉不过了,莫过于「天才,辍学和车库」,这似乎已经成为了硅谷大佬的刻板印象。 这次要讲的这…

VLA「司机大模型」问世。 本周二,理想全新纯电 SUV 理想 i8 正式上市,其搭载的全新一代 VLA 辅助…

本文第一作者是自南洋理工大学的博后朱贝尔和西湖大学的博士生王若禹,主要研究方向分别是 Robust Machi…
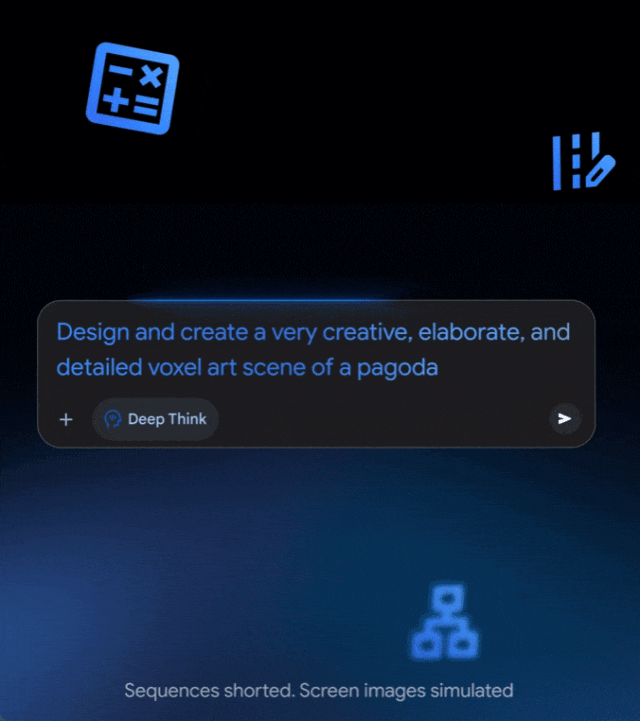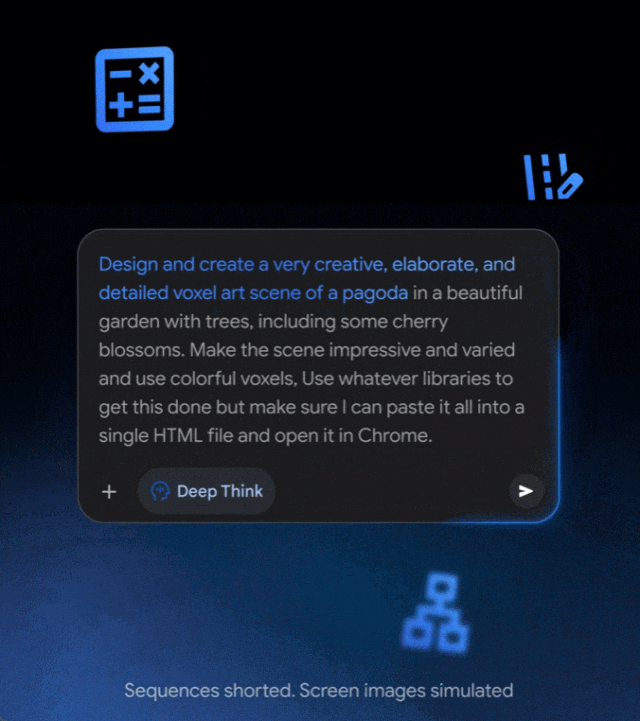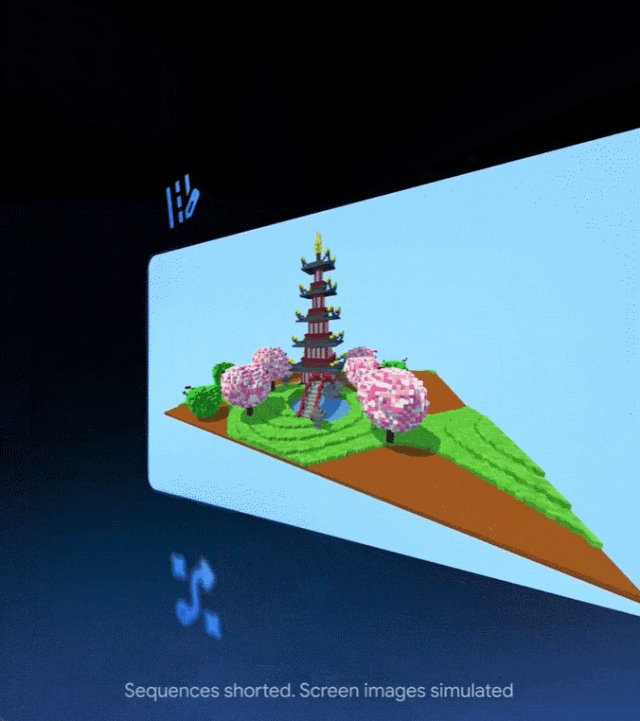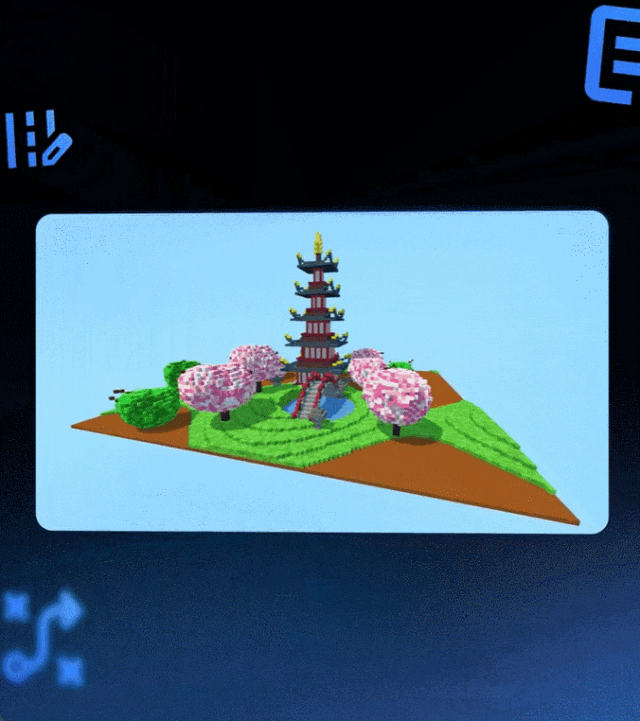
网友:Deep Think 简直太疯狂了。 本周五,谷歌宣布向 Google AI Ultra 订阅用户推出 …

奕起热爱,派生精彩。8月1日,东风奕派汽车科技公司战略发布会暨新车发布会在武汉隆重举行。此次发布会不仅是东风奕…
8月1日,2025年腾讯算法大赛正式开赛,全球超8400名技术精英将围绕”全模态生成式推荐R…